ANÁLISE
ESTRUTURADA
DE SISTEMAS
ANÁLISE
ESTRUTURADA
DE SISTEMAS
de CHRIS GANE
Faculdade de Tecnologia de Sorocaba
Curso Superior de Tecnologia em Processamento de Dados
Metodologia
em Análise e Projeto de Sistemas
Professor:
Luiz Forti
Anderson Ferreira Nascimento
Danilo Bordini
Fabiano Corrêa Moraes
Marcelo de Souza Canelli
Mariana Borghi
Rodrigo Colasuonno Manso
Índice
1. Como projetar Diagramas de Fluxo de Dados .........................................4
2. Dicionário de Dados .................................................................................8
3. Analise e Apresentação
lógica do processo ...........................................11
4. Definindo o Depósito de dados
...............................................................15
5. Requisitos de Resposta
...........................................................................17
6.
Como usar as ferramentas : Uma Metodologia Estruturada ...................19
7 Como derivar um Projeto
Estruturado do Modelo Lógico ......................21
8. Passos para a
implementação de um sistema .........................................23
1 Como projetar Diagramas de Fluxo de Dados
A idéia de um gráfico para representar o fluxo de dados através de um sistema não é recente; Martin e Estrin propuseram, em 1967, um gráfico de programa onde os fluxos de dados eram representados por setas e as transformações por círculos.
O diagrama de fluxo de dados é a ferramenta principal para entendimento e manipulação de um sistema de qualquer complexidade, juntamente com o refinamento desta notação para uso em análise.
1.1 Convenções Simbólicas
Examinemos detalhadamente as convenções simbólicas:
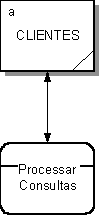
A – Entidade Externa
Entidades Externas são categorias lógicas de coisas ou pessoas que representam uma fonte ou destino para transações; por exemplo, clientes, empregados, fornecedores, segurados, etc. Elas também podem ser uma fonte ou um destino específico, como Departamento de Contas, Receita Federal, armazém.
Uma entidade externa pode ser representada por um quadrado sólido. Como referência à entidade, esta pode ser identificada por uma letra minúscula no canto superior à esquerda.

Para evitar o cruzamento de linhas de fluxo de dados, a mesma entidade pode ser desenhada mais de uma vez no mesmo diagrama; as duas (ou mais) caixas, por entidade, podem ser identificadas por uma linha inclinada no canto inferior à direita, como abaixo :

Ao identificarmos alguma coisa ou sistema como entidade externa, estaremos afirmando, implicitamente, que esta entidade está fora do alcance dos limites do sistema considerado.
B – Fluxo de Dados
O fluxo de dados é simbolizado por meio de uma seta, de preferência horizontal e/ou vertical, com a ponta indicando a direção do fluxo. Para facilitar o entendimento, especialmente nos esboços iniciais do diagrama, podemos usar uma seta com duas pontas no lugar de duas setas, quando os fluxos de dados aparecem em pares.
Cada fluxo pode ser considerado como um tubo por onde passam pacotes de dados. Podemos anotar uma descrição do conteúdo de cada fluxo ao longo de sua extensão. A descrição escolhida deve ser a mais significativa possível para os usuários que vão fazer a revisão do diagrama :

Em particular, quando esboçamos um DFD, podemos deixar de anotar a descrição caso esteja bastante óbvia para o revisor, mas aquele que criou o diagrama deve ser sempre capaz de fornecer uma descrição.
C – Processo
É necessário descrever a função de cada processo e, para facilitar a referência, fornecer uma identificação única para cada um, possivelmente associando-o a um sistema físico. Os processos podem ser representados por retângulos “em pé” com os vértices arredondados, divididos opcionalmente em três áreas :

- Identificação : pode ser um número, não tendo nenhum outro significado além do de identificar o processo.
- Descrição : deve ser uma sentença imperativa, idealmente consistindo num verbo ativo (extrair, computar, verificar) seguido de uma cláusula objeto, a mais simples possível, por exemplo :
Extrair – vendas mensais
Averiguar – se cliente tem crédito
- Local físico onde desempenhado: referência física, que indica como a função será fisicamente desempenhada (nome do programa físico, ou do departamento responsável)
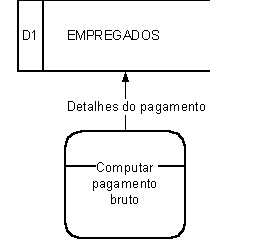
D – Depósito de Dados
Sem nos comprometermos quanto ao aspecto físico, detectaremos na análise a existência de certos lugares onde necessitamos definir dados como armazenados entre processos. Depósitos de dados podem ser simbolizados por um par de linhas paralelas horizontais, ligadas em uma das extremidades, largas somente o suficiente para comportar o nome. Para facilitar a referência, cada depósito pode ser identificado por um “D” e uns números arbitrários, contidos numa caixa na extremidade esquerda. O nome deve ser escolhido de modo que seja bem significativo para o usuário.

Quando um processo armazena dados, a seta de fluxo de dados aponta para o depósito de dados; por outro lado, quando o acesso a um depósito de dados é feito de forma a realizarmos apenas leitura, é suficiente mostrarmos o grupo de elementos de dados recuperados, no fluxo de dados que está saindo.
2. Dicionário de Dados
Def.: local estruturado que contém a descrição do conteúdo dos fluxos, dos depósitos de dados e dos processos existentes em um ou mais sistemas.
Pelo fato do dicionário de dados abrigar, além das definições de dados, as informações a respeito dos processos e, sendo assim referentes à lógica do projeto, o dicionário de dados passa adquirir um sentido mais amplo. Segundo o autor o nome “diretório de projeto” seria o nome mais qualificado para o dicionário de dados.
2.1 Composição
de um Dicionário de Dados
As três características básicas que descrevem um dicionário de dados, com seus fluxos e depósitos de dados, em nível lógico, são:
1. Elementos de Dados (Campos): dados que não precisam ser decompostos para o fim a que se destinam. Exemplo: data.
2. Estruturas de Dados (Registros): é a composição de elementos de dados ou de outras estruturas de dados, ou ainda a mistura de ambas.
3. Fluxos de Dados e Depósitos de Dados: onde, fluxo de dados representa o caminho ao longo do qual as estruturas de dados viajam; e depósito de dados corresponde aos locais onde as estruturas de dados são armazenadas até serem requisitadas.
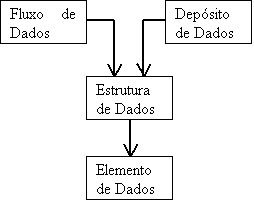 Diagrama da hierarquia de descrição de dados:
Diagrama da hierarquia de descrição de dados:
A informação mínima necessária para descrever um elemento de dado é seu nome e sua descrição.
Além disso, devem ser registrados os seguintes pontos à medida que vão sendo detectados:
· Pseudônimos para o elemento de dado
· Elementos de dados relacionados
· Domínio de valores e significados dos valores (contínuos ou discretos)
· Comprimento
· Codificação
· Outras informações para averiguação
Uma vez definidos os elementos de dados, para obtermos uma descrição das estruturas de dados basta que se especifique seu nome e os nomes dos elementos de dados que a compõe. Entretanto é preciso saber mais a respeito dessas estruturas, uma vez que os componentes de uma estrutura de dados podem ser obrigatórios, alternados, opcionais, ou ainda iterativos.
Além disso, dependendo da quantidade de processos pelos quais passa a estrutura de dados sem sofrer nenhuma alteração, faz sentido anotar os volumes dessa informação no nível de descrição das estruturas de dados.
Chega-se então ao topo (v. diagrama) da hierarquia
de descrição de dados, a descrição dos fluxos
e depósitos de dados.
A definição dos fluxos de dados requer: os nomes das estruturas de dados que o percorrem, a origem e o destino desse fluxo, os volumes de cada estrutura de dados ou transação (agrupadas por um período de tempo - semanal, mensal,...) e, se for necessário a descrição da implementação física atual do fluxo de dados. Importante salientar que um fluxo de dados é uma estrutura de dados em movimento.
Já os depósitos de dados são estruturas de dados estáticas, e são definidos basicamente por essas estruturas nele encontradas, mais os fluxos de dados que drenam e alimentam esse depósito. Pode-se, além disso, nesse nível definir algumas consultas simples ao depósito de dados (explicitas com mais rigor na seção de acesso imediato da especificação funcional).
Há ainda, a possibilidade de se acrescentar às informações do dicionário de dados referentes ao depósito de dados, detalhes como: chave primária, índices secundários, etc.
Com isso, a infra-estrutura básica de um dicionário de dados já estaria pronta, entretanto como já mencionado no início, cabe ao mesmo descrever sucintamente, também, os processos.
Na descrição de processos no dicionário de dados tem que constar as entradas e saídas do processo, o resumo da lógica empregada e, fazer uma referência ao trecho da documentação funcional, onde a lógica será encontrada.
Outras informações relevantes à composição de um dicionário de dados seriam: a descrição
das entidades externas e a descrição
de todas as demais entradas em um
glossário.
2.2 O que se
Obtém de um Dicionário de Dados ?
O dicionário de dados, como o próprio nome diz, tem a função de compilar todos os ”dados sobre dados” do sistema em desenvolvimento, isto é, atua como suporte à análise de sistemas.
Existem sete tipos diferentes de saídas fornecidas pelo dicionário de dados, sendo algumas delas conseguidas mais eficientemente através do uso de dicionário de dados automatizados (dda). São elas:
1. Listagens ordenadas de todas as entradas ou várias classes de entrada com detalhe parcial ou total ;
2. Relatórios compostos ;
3. Habilidade de cruzar referências ;
4. Como encontrar um nome a partir de uma descrição (dda);
5. Averiguação de consistência e integralidade ;
6. Geração de dados processáveis pelo computador (dda) ;
7. Obtenção das entradas do dicionário de dados através de programas já existentes (dda).
2.3 Dicionário de dados único para toda Empresa
A idéia de um dicionário de dados para toda uma organização é vista como uma ótima solução atendendo a vários pontos de vista:
· dos gerentes, que conseguirão avaliar com mais rapidez, precisão e segurança dados gerenciais (ex.: comparação de vendas e remessas);
· dos usuários, que terão como obter listas uniformes sobre os dados que poderão dispor ;
· dos analistas, que poderão iniciar novos projetos já dispondo das definições dos dados que serão usados no novo sistema ;
· dos projetistas e programadores, que conseguirão os dados necessários em seus programas em formato próprio para leitura e processamento pelo computador.
O que na época era uma grande idéia, esbarrava muitas vezes na resistência da própria empresa, posto que a implantação de um dicionário de dados único significa: resolver incompatibilidades, padronizar dezenas de aplicações e arquivos criados separadamente, ou ainda, agregar “hábitos” totalmente diferentes entre os departamentos.
Pode–se dizer que, atualmente o uso do “dicionário de dados único” é uma forte tendência entre as grandes e médias empresas, que estão cada vez mais devotas dos Sistemas de Gestão Integrada, mais conhecidos pela sigla ERP.
2.4 Dicionário
de Dados e Processamento Distribuído
O termo processamento distribuído ganhou cada vez mais força desde que foi imaginado pela primeira vez. A evolução e conseqüente barateamento da tecnologia, a tendência ao Downsizing e o uso aumentado das redes, levou a imagem do computador central, gigantesco e com altos custos de manutenção ao questionamento.
O fato é que o processamento distribuído possui inúmeras vantagens, dentre elas: maior confiabilidade, menor custo e maior flexibilidade.
No entanto, os perigos dessa tendência são as incoerências que podem surgir desse processamento distribuído. Por exemplo, cada filial de uma mesma empresa desenvolve aplicações próprias e incompatíveis.
É neste contexto que o uso de um dicionário de dados, com elementos de dados e estruturas de dados bem definidas, atua como base para integração dos sistemas da empresa.
3. Analise
e Apresentação lógica do processo
3.1 Arvores de Decisão:
As Arvore de decisão devem ser
utilizadas quando o numérico de decisões for pequeno e nem toda a combinação de
condições for possível. As arvore de decisão também são úteis para mostrar a
lógica de uma tabela de decisão aos usuários.
Erro! Argumento de opção desconhecido.
3.2 Tabela de Decisão:
A tabela de decisão deve ser
utilizada quando o numero de ações for grande e ocorrer muitas combinações de
condições. A tabela de decisão e mais indicada quando existirem duvidas de que
a árvore de decisão apresentara toda a complexidade possível. As tabelas de
decisão podem lidar com qualquer numero de ações, numerosas combinações de
condições podem dificultar o manuseio.
|
Condices |
1 |
2 |
3 |
4 |
|
1. Categoria (X,Y) |
X |
Y |
X |
Y |
|
2.
VALOR_CAPITAL_ATUAL = R$ 1.000,00 (<, >=) |
|
|
|
|
|
Ações |
|
|
|
|
|
1. Faça Depreciação
igual à (% do VALOR_CAPITAL_ATUAL) |
100 |
20 |
35 |
35 |
|
2. Faça
VALOR_NOVO_CAPITAL igual a (% do VALOR_CAPITAL_ATUAL) |
0 |
80 |
65 |
65 |
3.3 Portugués Estruturado
O português estruturado apresenta uma precisão de programa
de computador, mas não e um programa de computador. Não há especificação de
leitura e gravação de arquivos físicos, nenhuma preparação de contadores ou
chaves, ou qualquer projeto físico. O procedimento como está escrito, poderá
ser seguido por um funcionário embora pudéssemos apresentar as instruções de
forma diferente.
3.3.1 Tipos de instrucoes:
Instrucões
de caso:
SE
ENTAO SE
ENTAO
LOGO
SENAO
LOGO
Instruções de loop
REPETIR XXX ATE CONDICAO
Ou
REPETIR XXX ENQUANTO CONDICAO
3.3.2 Pseudocódigo
O pseudocódigo é um aperfeiçoamento do português
estruturado onde encontramos instruções de inicialização, termino, acesso e
gravação de arquivos.
3.3.3
Português logicamente compacto
O português estruturado embora produzindo uma
declaração lógica precisa e completa, utiliza-se de palavras em excesso e de
notação desconhecida para ser ideal na apresentação a usuários. Para
apresentarmos as instruções lógicas a um leigo utilizamos o português
logicamente compacto
As operações seqüências são apresentadas como
instruções imperativas para serem desempenhadas de forma rotineira (simples e
direta)
As estruturas se-entao-senao-logo são apresentadas
com notação decimal e deslocamento vertical:
5
5.1
5.1.1
5.1.1.a
Conclusão:
A tabela a seguir apresenta os pontos fortes e
fracos relativos a quatro ferramentas para lógica de processo que discutimos
neste capitulo. Esta tabela leva em conta oito considerações classificadas em
três áreas básicas:
1. Ate que ponto o analista encontra facilidade para usar as
ferramentas?
2. É fácil para a comunidade de usuários usar as ferramentas?
3. É fácil para o projetista ou programador usar as
ferramentas?
|
USO |
ARVORES DE DECISAO |
TABELAS DE DECISAO |
PORTUGUES ESTRUTURADO |
PORTUGUES COMPACTO |
|
Verificação lógica |
Moderado |
Muito bom. |
Bom |
Moderado |
|
Exibir estrutura lógica |
Muito bom (mas somente decisão) |
Moderado (somente decisão) |
Bom (todas) |
Moderado (todas, mas dependente do autor) |
|
Simplicidade (facilidade de uso) |
Muito bom |
De pobre a muito pobre |
Moderado |
Bom |
|
Verificação pelo usuário |
Bom. |
Pobre (a menos que o usuário seja treinado) |
De pobre a moderado (um pouco de jargão) |
Bom |
|
Especificação de programa |
Moderado |
Muito bom. |
Muito bom |
Moderado |
|
Leitura pelo computador |
Pobre |
Muito bom |
Muito bom |
Moderado |
|
Averiguação pelo computador |
Pobre |
Muito bom |
Moderado |
Pobre |
|
Alterabilidade |
Moderado |
Pobre |
Bom |
bom |
Exemplo:
Se VALOR_CAPITAL_ATUAL <= 1.000
Se CATEGORIA = X
Faça DEPRECIACAO = VALOR_CAPITAL_ATUAL
Faça VALOR_NOVO_CAPITAL = 0
Caso
Contrario (Categoria = Y)
Faça DEPRECIACAO = VALOR_CAPITAL_ATUAL * 0,20
Faça VALOR_NOVO_CAPITAL = VALOR_CAPITAL_ATUAL *
0,80
Caso Contrário (VALOR_CAPITAL_ATUAL >= 1.000)
Faça DEPRECIACAO = VALOR_CAPITAL_ATUAL * 0,35
Faça VALOR_NOVO_CAPITAL = VALOR_CAPITAL_ATUAL * 0,65
4. Definindo o
Depósito de dados
Um bom depósito obtém-se observando com atenção aos fluxos.
Os fluxos dizem exatamente quais serão os dados armazenados tomando atenção a seguinte premissa: tudo que entra deve sair e tudo que sai deve entrar. Ou seja:
No fluxo aparece a necessidade de se obter certos dados e outros não, apenas os dados necessários (que saem) devem entrar.
Eliminar as redundâncias é o próximo passo.
4.1 Normalização
Consiste basicamente na reorganização do depósitos de dados para remover grupos repetitivos.
É necessário desmembrar a estrutura dos depósitos de dados de menores grupos inter-relacionados.
Codd (um especialista em informática que na época trabalhava para a IBM) estabeleceu a existência de três tipos de relações normalizadas, Definiremos a seguir cada uma destas.
4.1.1 1ª Forma Normal
Qualquer relação normalizada (uma estrutura de dados sem grupos repetitivos) está automaticamente na 1FN, não importa o grau de complexidade de sua chave ou que inter-relacionamentos possam existir entre os elementos de dados componentes. Relações na primeira forma normal podem estar sujeitas as dois tipos de complexidades:
1. Se a chave-primária estiver concatenada, alguns domínios que não sejam chaves poderão depender de parte da chave, e não da chave toda.
2. Alguns do domínios que não são chaves podem estar inter-relacionados.
4.1.2 2ª Forma Normal
Uma relação está na 2FN
se todos os domínios que não são chaves forem completamente dependentes
funcionalmente da chave-primária.
4.1.3 3ª Forma Normal
Uma relação normalizada está na terceira forma normal se:
1. Quando todos os domínios que não são chaves formem completamente dependentes da chave-primária.
2. E quando nenhum domínio que não seja chave for dependente funcionalmente de qualquer outro domínio que não seja chave.
Então, para transformarmos uma relação na 2FN em uma relação na 3FN, examinamos cada um dos domínios que não são chaves para ver se cada um deles é independente dos demais domínios que não são chaves e removemos qualquer dependência mútua.
A 3NF é a mais simples representação de dados que podemos obter. Ela representa um tipo de “bom senso inspirado”; muitas vezes, quando condensamos o resultado, acabamos por dizer: “É claro! Esses são os elementos de dados básicos que descrevem um cliente (ou componente, ou emprego, etc.)”.
5. Requisitos de Resposta
Faz parte da análise obter prioridades que os usuários dão às consultas ou perguntas.
Mas antes, é necessário conhecermos algumas técnicas físicas envolvidas em acesso imediato.
5.1 Conceitos de Entidades e Atributos
As coisas do mundo rela apresentam várias propriedades: uma máquina tem dimensões, peso e número de identificação; uma pessoa tem nome, endereço, código de identificação, data de contratação, salário e assim por diante. Quando descrevemos um dados, uma coisa (ou uma classe de coisas) é tida como entidade; os elementos de dados que descrevem as propriedades das coisas são atributos da entidade.
5.2 Seis Tipos Básicos de Perguntas
Podemos descrever os seis tipos básicos de perguntas ou consultas em termos de entidades, seus atributos e valores que esses atributos possam ter.
Pergunta tipo 1.
Dada uma certa entidade (E), qual é o valor de um certo atributo (A)?
A(E)=?
“Dada a peça de número B232, qual o valor de seu peso?”
Pergunta tipo 2.
Dado o valor de um certo atributo, que entidades são especificadas?
A(?){= # > <}V
“Dado um peso de um quilo (A), que peças (E) têm este valor?”
ou
“Dado um título de ENGENHEIRO, que funcionários têm tal título?”
Pergunta tipo 3.
Dados uma certa entidade e um valor, que atributo(s) da entidade combina(m) esse valor?
?(E){= # > <}v
“Dado o produto de número B232, que dimensão (se houver) excede a 30 cm?”
Pergunta tipo 4.
Semelhante ao tipo 1, exceto que pede todos os valores de todos os atributos, ao invés de apenas um atributo
A(E)=?
“Liste os detalhes do empregado número 26622.”
Pergunta tipo 5.
Semelhante ao tipo 2, mas, como a do tipo 4, também é global quando ao fato de pedir todos os valores de um atributo, para todas as entidades.
A(?)=?
“Listar os pesos de todos as peças.”
Pergunta tipo 6.
Equivalente ao tipo 3, pois todos os atributos de todas as entidades que possuam um certo valor.
?(?){= # > <} V
“Liste cada peça que tenha qualquer dimensão maior que 15 cm.”
6. Como usar
as ferramentas : Uma Metodologia Estruturada.
6.1
O Estudo Inicial
Perguntas que devem ser respondidas pelo Estudo Inicial:
- Que há de errado com a situação atual?
- Que melhoramento é possível?
- Quem será afetado pelo novo sistema?
Quando uma empresa deseja fazer algum tipo de modificação em seu sistema atual, os gerentes geralmente fazem pedidos ao serviço de Processamento de Dados, solicitando estas alterações. Através destes pedidos, o analista começara o Estudo Inicial, que pode levar de dois dias à quatro semanas. Tendo em vista que estes pedidos tem que ser analisados antes de qualquer tipo de reunião ou questionários ao gerentes e outros funcionários da empresa.
Segundo passo é entrevistar os gerentes em questão. Com isso se obtém mais informações, do que só através de pedidos escritos.
E por último, o analista deve conhecer muito bem o sistema atual e analisar o plano de desenvolvimento de PD, se tiver.
No final do Estudo Inicial, o analista já deve ter a magnitude que poderão advir do novo sistema a ser implantado. Se a empresa vai economizar 30% em dois anos ou visará lucro na margem de seis meses. Deixando bem claro que não é a hora certa do analista passar um preço pelo projeto elaborado.
Tendo tudo isso em mãos, o analista pode-se então passar para a segunda parte da Análise.
6.2
O Estudo Detalhado
O Estudo Inicial será então revisto pelos gerentes, dizendo-lhe então se a implantação do projeto pode continuar ou não. Se a resposta for sim, passa-se então para a segunda etapa, que consiste em Definir os usuários do novo sistema e Construir um Modelo Lógico do Sistema existente.
6.3
Definir os
usuários:
Uma empresa geralmente possui rês níveis de usuários.
1 Os gerentes-sênior
2 Os gerentes de segunda linha
3 Os funcionários em geral
Para cada usuário serão estipuladas diferenças quanto à :
1 Nomes e responsabilidades;
2 Funções e Relacionamentos dos departamentos afetados;
3 Descrição dos trabalhos de rotina;
Por exemplo, um gerente de vendas, prefere o prazo de entrega mais curto, pois assim ele vende mais e satisfaz também mais seus clientes. Mas o gerente de compras, já prefere um prazo mais longo, pois assim ele pode programar melhor a produção economizando mais.
Outros gerentes tendem a se preocupar mais com o desempenho do sistema e não com o quadro estratégico.
Enfim, cada usuário terá um desenvolvimento específico à parte.
6.4
Construir um Modelo
Lógico do Sistema existente
Com as informações adquiridas até o momento, pode-se então fazer um esboço do diagrama de fluxo de dados. O sistema existente em questão, seria um que possuísse sistemas envolvidos manuais e outros automatizados. Mas como o analista saberia o que se enquadraria dentro do estudo ou não? Para isso ele realiza então um diagrama de fluxo lógico, pois assim ele reduz as redundâncias e duplicidades de informações, e saberá também informar quais são as entradas e saídas do sistema, facilitando então o restante da análise. Deixando claro que a análise lógica do sistema, não é examinar o programa em si e sim a parte externa dele.
Com o fim desta segunda etapa, o analista deve possuir as seguintes informações:
· Definição dos usuários para o novo sistema;
· Modelo Lógico do Sistema existente;
· Declaração de rendimento aumentado/Custo evitado/Serviço aperfeiçoado.
· Estimativas do provável custo de reposição do sistema/Tempo para a próxima fase.
7 Como derivar um
Projeto Estruturado do Modelo Lógico
7.1
Objetivos do
Projeto
O objetivo mais importante do projeto é entregar as funções requisitadas pelo usuário. Para isso, existem três objetivos principais que o analista deve se lembrar quando desenvolve um projeto:
- Desempenho (ou rapidez com que o projeto efetua o trabalho do usuário dado um determinado recurso de máquina);
- Controle (até que ponto o projeto está seguro contra falhas humanas, defeitos de máquinas ou danos propositais);
- Alterabilidade (facilidade de alteração de um projeto);
Falaremos agora um pouco sobre cada um.
7.1.1 Desempenho
Geralmente o desempenho é expresso em termos de :
throughput (transações/cálculos por hora) ou
tempo de processamento;
tempo de resposta;
Temos cinco fatores que afetam o desempenho de um sistema:
Número de arquivos intermediários de um sistema;
Número de vezes em que um determinado arquivo é pesquisado;
Número de buscas em relação à um arquivo em disco;
O tempo gasto na chamada aos programas e outras tarefas indiretas do sistema;
O tempo dispendido para a execução de programas em si;
7.1.2 Controle
Dependendo do sistema terá que ser construído controles de todos os tipos. Eis alguns aspectos de controle a seguir:
O uso de dígitos verificadores com números predeterminados (utilizados muito em bancos), onde o último número é o resultado de uma fórmula aplicada nos demais números;
O uso de controles de totais em “batch”;
A criação de diários e controles de auditoria;
A limitação do acesso aos arquivos (quem tem acesso a quê, quem altera o quê);
7.1.3 Alterabilidade
Seria dizer a medida do tempo necessário para efetuar qualquer mudança do sistema, seja removendo uma falha ou fazendo algum aperfeiçoamento. Assim simplificando o trabalho de um novo analista ou do atual.
8. Passos para a
implementação de um sistema
8.1 Metodologias à serem aplicadas
Existem dois tipos de metodologias à serem utilizadas :
- Em linha reta (o “ideal”)
- Em espiral (o “real”)
No passado diziam-se que para um projeto ser bem administrado, tinha que ser utilizado o desenvolvimento em linha reta, desde o estudo de viabilidade passando pela análise e projeto até o teste, a aceitação e a operação.

Análise Projeto Codificação Teste
( o “ideal no andamento do projeto)
Neste tipo de metodologia, primeiro era realizado todo o projeto para depois haver a implementação. Se ocorresse um erro, teria que alterar todo o projeto novamente.
Análise Projeto Codif. Teste
( a realidade dos projetos em espiral)
Esta técnica, engloba um projeto onde há a realização de alguma análise, depois de um pouco de projeto, voltando para uma análise mais detalhada, depois mais projeto, em seguida talvez uma codificação da versão 1, mais projeto e assim por diante. Assim se houver algum erro ou mudança a fazer, só terá que ser realizada em apenas alguns módulos e não em todo o projeto.
8.1.1
Treinamento de
analistas no uso das ferramentas e técnicas
Para utilizar todas as ferramentas apresentadas, o analista necessita de estudo e prática, tanto nelas quanto no software a ser utilizado para a implantação do projeto. Ele precisa entender os princípios do projeto estruturado e ser capaz de criticá-lo, mesmo que não vá produzi-los.
8.1.2
Orientação dos
usuários nos novos métodos
A orientação do usuário, geralmente feita à medida que cada projeto estruturado se inicia, deve cobrir os seguintes pontos :
· notação do diagrama de fluxo de dados;
· conceito de apresentar um menu de sistemas alternativos;
· conceito de desenvolvimento top-dow;
· declaração do envolvimento necessário por parte dos usuários;
· garantia de que as novas técnicas substituem o método existente;
É recomendável que os usuários recebam um treinamento para manipulação de todas as ferramentas e técnicas usadas na Análise Estruturada de Sistemas. Isto lhes proporcionará habilidade para pensar com mais precisão sobre seus negócios e requisitos, para comunicar suas idéias de forma padronizada ao analista e aos projetistas.
8.2
Benefícios do uso
da Análise Estruturada de Sistemas
Resumidamente :
8.3 mostrar claramente o que se construirá para que todos possam ter certeza de que se está construindo o sistema certo.
8.4 Desenvolver as alternativas e os detalhes com o mínimo possível de perda de tempo.